Merge changes with git diff and patch

Collaborate on file changes, with no Git hosting service necessary, using the Linux git diff and patch commands.

|
Linux, CDN (@picocdn), WiFi, Open Source, etc etc.. More read here - https://t.co/QSkJFNaXsc
|

No excuses. We don't write documentation because writing clearly is extremely hard.
The post Why programmers don’t write documentation first appeared on Kislay Verma.

 MariaDB 10.5 has an excellent engine plugin called “S3”. The S3 storage engine is based on the Aria code and the main feature is that you can directly move your table from a local device to S3 using ALTER. Still, your data is accessible from MariaDB client using the standard SQL commands. This is a great solution to those who are looking to archive data for future references at a low cost. The S3 engine is READ_ONLY so you can’t perform any write operations ( INSERT/UPDATE/DELETE ), but you can change the table structure.
MariaDB 10.5 has an excellent engine plugin called “S3”. The S3 storage engine is based on the Aria code and the main feature is that you can directly move your table from a local device to S3 using ALTER. Still, your data is accessible from MariaDB client using the standard SQL commands. This is a great solution to those who are looking to archive data for future references at a low cost. The S3 engine is READ_ONLY so you can’t perform any write operations ( INSERT/UPDATE/DELETE ), but you can change the table structure.
In this blog, I am going to explain the details about the S3 engine’s implementation and aspects. And in the end, I compare the performance results from both Local and S3 engine tables.
The S3 engine is alpha-level maturity and it will not load by default during MariaDB startup. You have to enable the S3 engine as follows:
[mysqld] plugin-maturity = alpha
You also need to configure your S3 credentials in the MariaDB config file so that MariaDB can authenticate the connection and communicate with the S3 bucket. My config file looks like this:
[mysqld] server-id = 101 plugin-maturity = alpha log_error = /data/s3_testing_logs/mariadb.log port = 3310 #s3 s3=ON s3_access_key = xxxxxxxxxxxx s3_secret_key = yyyyyyyyyyyyyyyyyyyyyyy s3_bucket = mariabs3plugin s3_region = ap-south-1 s3_debug = ON
Note: From a security perspective, your AWS credentials are plaintext. A new key pair should be created specifically for this plugin and only the necessary IAM grants be given.
After configuring the parameters, you need to restart MariaDB to apply the settings. After the restart, you can install the plugin as follows.
MariaDB [(none)]> install soname 'ha_s3'; Query OK, 0 rows affected (0.000 sec) MariaDB [(none)]> select * from information_schema.engines where engine = 's3'\G *************************** 1. row *************************** ENGINE: S3 SUPPORT: YES COMMENT: Read only table stored in S3. Created by running ALTER TABLE table_name ENGINE=s3 TRANSACTIONS: NO XA: NO SAVEPOINTS: NO 1 row in set (0.000 sec)
Now the S3 engine is ready to use.
You can move the table to the S3 engine by using the ALTER. For testing, I have created the table “percona_s3” at my lab.
MariaDB [s3_test]> show create table percona_s3\G *************************** 1. row *************************** Table: percona_s3 Create Table: CREATE TABLE `percona_s3` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(16) DEFAULT NULL, `c_date` datetime DEFAULT current_timestamp(), `date_y` datetime DEFAULT current_timestamp(), PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 1 row in set (0.000 sec) [root@ip-172-31-19-172 ~]# ls -lrth /var/lib/mysql/s3_test/* | grep -i percona_s3 -rw-rw---- 1 mysql mysql 1019 Jul 14 01:50 /var/lib/mysql/s3_test/percona_s3.frm -rw-rw---- 1 mysql mysql 96K Jul 14 01:50 /var/lib/mysql/s3_test/percona_s3.ibd
Physically, you can see both .frm and .ibd files once the table is created (default InnoDB). I am going to convert the table “percona_s3” to the S3 engine.
#MariaDB shell MariaDB [s3_test]> alter table percona_s3 engine=s3; Query OK, 0 rows affected (1.934 sec) Records: 0 Duplicates: 0 Warnings: 0 MariaDB [s3_test]> show create table percona_s3\G *************************** 1. row *************************** Table: percona_s3 Create Table: CREATE TABLE `percona_s3` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(16) DEFAULT NULL, `c_date` datetime DEFAULT current_timestamp(), `date_y` datetime DEFAULT current_timestamp(), PRIMARY KEY (`id`) ) ENGINE=S3 DEFAULT CHARSET=latin1 PAGE_CHECKSUM=1 1 row in set (1.016 sec) #Linux shell [root@ip-172-31-19-172 ~]# ls -lrth /var/lib/mysql/s3_test/* | grep -i percona_s3 -rw-rw---- 1 mysql mysql 1015 Jul 14 01:54 /var/lib/mysql/s3_test/percona_s3.frm
Note: You will get the error “ERROR 3 (HY000):” if you enabled SELINUX, or if anything related to S3 access is misconfigured.
After converting to the S3 engine, you can see only the .frm file. The data has been migrated out of InnoDB and into the S3 engine storage format.
[root@ip-172-31-19-172 ~]# aws s3 ls s3://mariabs3plugin/s3_test/percona_s3/ PRE data/ PRE index/ 2020-07-14 01:59:28 8192 aria 2020-07-14 01:59:28 1015 frm [root@ip-172-31-19-172 ~]# aws s3 ls s3://mariabs3plugin/s3_test/percona_s3/data/ 2020-07-14 01:59:29 16384 000001 [root@ip-172-31-19-172 ~]# aws s3 ls s3://mariabs3plugin/s3_test/percona_s3/index/ 2020-07-14 01:59:28 8192 000001
Note: S3 will split the data and index pages and store them separately in respective folders.
For testing, I created the below table on S3. Let’s test the commands one by one.
MariaDB [s3_test]> select * from percona_s3; +----+-----------------+---------------------+---------------------+ | id | name | c_date | date_y | +----+-----------------+---------------------+---------------------+ | 1 | hercules7sakthi | 2020-06-28 21:47:27 | 2020-07-01 14:37:13 | +----+-----------------+---------------------+---------------------+ 1 row in set (1.223 sec) MariaDB [s3_test]> pager grep -i engine ; show create table percona_s3; PAGER set to 'grep -i engine' ) ENGINE=S3 AUTO_INCREMENT=2 DEFAULT CHARSET=latin1 PAGE_CHECKSUM=1 | 1 row in set (0.798 sec)
With all three statements, the query will return the “ERROR 1036: read only”.
Sample output:
MariaDB [s3_test]> insert into percona_s3 (name) values ('anti-hercules7sakthi');
ERROR 1036 (HY000): Table 'percona_s3' is read only
MariaDB [s3_test]> select * from percona_s3; +----+-----------------+---------------------+---------------------+ | id | name | c_date | date_y | +----+-----------------+---------------------+---------------------+ | 1 | hercules7sakthi | 2020-06-28 21:47:27 | 2020-07-01 14:37:13 | +----+-----------------+---------------------+---------------------+ 1 row in set (1.012 sec)
MariaDB [s3_test]> alter table percona_s3 add index idx_name (name); Query OK, 1 row affected (8.351 sec) Records: 1 Duplicates: 0 Warnings: 0
MariaDB [s3_test]> alter table percona_s3 modify column date_y timestamp DEFAULT current_timestamp(); Query OK, 1 row affected (8.888 sec) Records: 1 Duplicates: 0 Warnings: 0
MariaDB [s3_test]> drop table percona_s3; Query OK, 0 rows affected (2.084 sec)
Note: DROP TABLE will completely remove the data and index pages from S3 as well.
In short, the S3 will allow the read commands and the structure modification commands. Changing or adding any data into the S3 is restricted. MariaDB community is planning to allow the BATCH UPDATE (single user) on S3. Right now, if you need to change any data on S3 tables, you need to follow the below procedure:
You can also query the metadata from INFORMATION_SCHEMA and retrieve the metadata using the SHOW commands.
In this section, I am going to compare the query results on both the S3 engine and Local. We need to consider the below points before going to the test results.
At S3:
MariaDB [s3_test]> select count(*) from percona_perf_compare; +----------+ | count(*) | +----------+ | 14392799 | +----------+ 1 row in set (0.16 sec)
At local:
MariaDB [s3_test]> select count(*) from percona_perf_compare; +----------+ | count(*) | +----------+ | 14392799 | +----------+ 1 row in set (18.718 sec)

Count(*) is faster on S3engine. S3 tables are read_only, and it might display the stored value like MyISAM.
At S3:
MariaDB [s3_test]> pager md5sum; select * from percona_perf_compare; PAGER set to 'md5sum' 1210998fc454d36ff55957bb70c9ffaf - 14392799 rows in set (16.10 sec)
At Local:
MariaDB [s3_test]> pager md5sum; select * from percona_perf_compare; PAGER set to 'md5sum' 1210998fc454d36ff55957bb70c9ffaf - 14392799 rows in set (11.16 sec)

At S3:
MariaDB [s3_test]> pager md5sum; select * from percona_perf_compare where id in (7196399); PAGER set to 'md5sum' 13b359d17336bb7dcae344d998bbcbe0 - 1 row in set (0.22 sec)
At Local:
MariaDB [s3_test]> pager md5sum; select * from percona_perf_compare where id in (7196399); PAGER set to 'md5sum' 13b359d17336bb7dcae344d998bbcbe0 - 1 row in set (0.00 sec)

S3 engine is pretty good with COUNT(*). And, if we retrieve the actual data from S3, we can see little delay compared to local.
I have conducted the above tests with the default S3 settings. As per the MariaDB document, we can consider the below things to increase the performance on S3:
I would say the performance also depends on the disk access speed and network health between server and S3. Consider the below points:
I am working with Agustin on our next blog on this, covering the S3 engine compression. Stay tuned!
A few years ago I was working on a contract negotiation with Splunk, and we kept running into what felt like a pretty unreasonable pricing structure. They wanted some number of millions of dollars for a three year license, which felt like a high price to pay for thirty-two ascii characters in a particular sequence. Even with the license, we'd still be the ones operating it and paying for the capacity to run it.
We decided to negotiate by calculating the cost of running our own ELK Stack cluster, determined by means of the appropriate solution of solid numbers and hand waving. We used this calculation to establish Splunk's value to us and ultimately got Splunk to come down to our calculated value instead of their fee structure, although I suspect we might have overpriced the value a bit and landed too high within the zone of possible agreement.
Recently Calm has been considering if we should move parts of our workflow to a headless CMSes, and consequently I've been thinking a bit more about how to make these sorts of build versus buy decisions, and in particular how to evaluate the "buy" aspect. Ultimately, I think it comes down to risk, value, and cost.
Using a vendor is taking on an outstanding debt. You know you will have to service that debt's interest over time, and there's a small chance that they might call the debt due at any point.
From a risk perspective, calling the debt due isn't the vendor holding you hostage for a huge sum, although certainly if there's little competition the risk of price increases is real. Rather, the most severe risks are the vendor going out of business, shifting their pricing in a way that's incompatible with your usage, suffering a severe security breach that makes you decide to stop working with them, or canceling the business line (which some claim has undermined Google's abiltiy to gain traction on new platforms).
Some risks can be managed through legal contracts. Other risks can be managed by purchasing insurance. Other sorts you simply have to decide whether they're acceptable.
In the build versus buy decision, most companies put the majority of their energy into identifying risk, which has its place, but often culminates in a robust not invented here culture that robs the core business of attention. To avoid that fate, it's important to spend at least as much time on the value that comes from buy decisions.
Businesses succeed by selling something useful to their users. Work directly towards that end is core work, and all other work is auxiliary work. Well-run, efficiency-minded businesses generally allocate just enough resources to auxiliary work to avoid bottlenecks in their core work, reserving the majority of their resources for core work. This efficiency-obsession is a subtle mistake, because it treats auxiliary work as cost centers disconnected from value creation.
In reality, value is created by the overall system, which includes auxiliary work. Many companies create more value from their auxiliary work than their core work, for example a so-so product supported by extraordinary marketing efforts. Other companies sabotage their core work by underinvesting in the auxiliaries, for example a company of engineers eternally awaiting design guidance.
To calculate the value of a vendor, compare the vendor's offering against what you're willing to build today. The perfected internal tool will always be better than the vendor's current offering, but you're not going to build the perfected internal tool right now, what will you actually build?
Also, how will the quality and capabilities of the two approaches diverge over time? Most companies, particularly small ones, simply can't rationally invest into improving their internal tools, such that they get worse over time relative to an active vendor. If you're assuming the opposite, dig into those assumptions a bit. Vendors selling those internal tool have a totally different incentive structure than you do, and it's an incentive structure that requires they make ongoing investments in their offering.
At a certain point you may reach your own internal economies of scale that support ongoing investment into internal tooling. Uber famously built their own replacement for both Greenhouse and Zendesk after reaching about 2,000 engineers, but they relied on vendors extensively up until they reached that point.
One way that folks sometimes discount vendors' value to zero is they worry that the vendor simply won't be good enough to use at all. This implies the existence of a boolean cutoff in quality between sufficient and insufficient quality. This is a rigid mindset that doesn't reflect reality: quality is not boolean. There will be gaps in vendor functionality, and you should absolutely identify those gaps and understand the cost of addressing them, but avoid falling into a mindset that your requirements are fixed absolutes.
When it comes to build versus buy, the frequently repeated but rarely followed wisdom is good advice: if you're a technology company, vendors usually generate significant value if they're outside your company's core competency; within your core competency, they generally slow you down.
Once you understand the value a vendor can bring, you then have to consider the costs. The key costs to consider are: integration, financial, operating and evolution.
Integration costs are your upfront costs before the vendor can start creating value. This is also the cost of replacing the vendor if the current vendor were to cease to exist at some point in the future. This is where most vendor discussions spend the majority of their time.
Financial costs are how much the contract costs, including projecting utilization over time to understand future costs. This is another area that usually gets a great deal of attention during vendor selection processes, but often with a bit too much emphasis on cost-cutting and not enough on value.
Operating costs are the cost of using the vendor, and in my experience are rarely fully considered. This includes things like vendor outages or degradations, as well as more nuanced issues like making mandatory integration upgrades as the vendor evolves their platform. Stripe's Payment Intents API is far more powerful than the previous Charge API, but there's a large gap between knowing a more powerful solution is available and learning last year that PSD2's SCA requirements meant you had to upgrade to keep selling to buyers in the European Union.
How you want to use a vendor will shift over time, which makes evolution costs essential to consider, and similar to operating costs are an oft neglected consideration. This is where vendor architecture matters a great deal, and well-designed vendors shine. An example of good vendor architecture is headless CMSes: they're flexible because they're focused on facilitating one piece of the workflow. If some piece of the workflow doesn't fit for a niche workflow you support, just cut that one piece away from the headless CMS: you don't have to replace the entire thing at once.
Some vendor solutions try to create a crushing gravity that restricts efforts to move any component outside their ecosystem, and these are the vendors to avoid. Folks often focus on things like being vendor-agnostic, e.g. the ability to wholesail migrate from one vendor to another, when I think it's usually more valuable to focus on being vendor-flexible: being able to move a subset of your work to a better suited tool.
Your total cost model should incorporate all of these costs, and becomes a particularly powerful tool in negotiating the contract.
Once you've thought through the value, risk and cost, then at some point you have to make a decision. My rule of thumb is to first understand if there are any sufficiently high risks that you simply can't move forward. If the risks are acceptable, then perform a simple value versus cost calculation and accept the results!
Generally the two recurring themes I've seen derail this blindingly obvious approach are legal review (outsized emphasis on unlikely or mitigatable risks) and unfungible budgets (overall cheaper to use vendor, but company views headcount budget and vendor budgets as wholy distinct).
These are both sorts of bureaucratic scar tissue that accumulate from previous misteps, and aim to protect the business. On average, they likely are creating the right outcomes for the company, but for specific decisions they might not be. If you believe strongly enough that this is one of those exceptions, then ultimately I've found you need an executive sponsor to push it through.
Throwing in one more thought before wrapping this up, I've found that many companies are quite bad at vendor management and are quite good at building things. As such, their calculations always show that vendors are worse than building it themselves, and that's probably true for them in their current state.
To get the full value from vendors, you have to invest in managing vendors well. A company that does this extraordinarily well is Amazon, who issue their vendors quarterly report cards grading their performance against the contract and expectations. Getting great results from vendors requires managing them. If you neglect them and get bad results, that's on you.
Of all the emotions I struggle with, the toughest one is Self-Doubt.
To give you an idea of our tenuous relationship, here are some of the questions Self-Doubt routinely asks me:
“Hey, you. Yeah, you. Will your work ever be good enough?”
“Do you really think you’ll be able to grow this blog into something financially viable?”
“Shouldn’t you just give up now and do something else instead?”
These questions are no fun to face, and the most frustrating part is that they can appear at any random moment. Even when things are going well and I’m feeling good about my work, all it takes is for me to check my website analytics or read another person’s great article for me to question everything I’m doing.

I know I’m not the only one that struggles with Self-Doubt, as it largely comes with the territory of any worthwhile endeavor. However, the interesting thing is that it’s both a bug and a feature; amidst the haze of negativity it stirs up, there is a utility to it as well.
Self-Doubt is useful because it indicates how important something is in our lives, and whether or not that endeavor is worth pursuing deeply. If you had no doubts whatsoever about the work you’re doing, it likely means that you don’t care enough about it, as brash certainty and carelessness tend to be close cousins.
It’s rare to hear someone question the quality of their work at a job they hate – they understand that “good enough” is a satisfactory outlook to get on with their day. Doubt has no room to surface if indifference is running the show.

So if you find yourself doubting what you’re doing, then congratulations, that means you’ve found something worth your time. But don’t celebrate too much, as the other side of Self-Doubt is a terror of a place to navigate.
If left unchecked, Self-Doubt can paralyze and derail you from doing the things that matter most. It can prevent you from doing meaningful work in fear of being rejected, from having the patience to play the long game, and perhaps most damning, from making the most out of this one life you have.
The ability to silence Self-Doubt is a superpower, and will be one of the greatest assets you can have throughout your creative journey. But in order to cultivate this skill, we must first understand the mechanisms Self-Doubt operates under to appear in the first place. If we can get a good look into the rules it plays by, then we will be better equipped to face it whenever one of those patterns become evident.
Well, fortunately for us, the timing couldn’t be any better. I had a ferocious wrestling session with Self-Doubt the other day, and during the flurry of the battle, it accidentally dropped its handy little rulebook on the ground after I successfully chased it back to its cave.

After leafing through the book, I was surprised to see how succinct it was, and how there were just three basic rules that governed the entirety of Self-Doubt’s existence. Sometimes the most complicated human emotions can be condensed into simple patterns, and it turns out Self-Doubt is no exception.
I want to share these three rules with you, but first, there’s a brief prologue in the book that we need to go over. This introduction is necessary because it dispels the most common misconception we have about Self-Doubt, and it is only after reviewing it where the three rules will make the most sense.
So with that said, let’s crack open this ancient rulebook, and dive right in.

It is often said that “you are your own worst enemy,” and this is a statement that creatives in particular love throwing around. The logic behind this cliche goes something like this:
“All doubts are internal struggles that are birthed from within. After all, no one is telling you to doubt yourself but you, right? Once you realize that you are creating your own fears, you have to snap out of it and defeat that inner voice that is stopping you from being your authentic self.”
Under this rationale, Self-Doubt arises as an independent barrier that you alone have constructed, and you alone must face. Everything starts – and ends – with you.

While it’s somewhat romantic to view Self-Doubt as a heroic solo endeavor, the reality is far from it.
Doubt only emerges because we live in a world where we compare our own progress against the progress of others. Whenever we doubt ourselves, what we are actually questioning is our ability to meet the expectations of what we think is possible. And like it or not, our expectations are built by the possibilities that other people have already reached, or are close to reaching.
After all, we wouldn’t be writers, cooks, or musicians if there were no writers, cooks, or musicians that demonstrated the viability of these art forms before us. This is why the line between inspiration and doubt can be thin – the very people that inspired us to pursue a calling can also make us doubt ourselves when we don’t think we’re reaching what they have attained.
What this reveals is that doubt doesn’t arise on our own accord; it comes about because we live amongst a vast Landscape of Creators that are influencing the expectations we set for ourselves. It is this network of peers, mentors, and public figures that motivate us to do great work, but can also make us question what we’re doing when we don’t think it aligns with what should be possible.

Ultimately, Self-Doubt is more about how you view your relationship with others, and less about a battle with yourself. Once we’re able to understand how our view of others affects our sense of progress, then we are better equipped to handle the fear that Self-Doubt throws at us.
Now that we’ve introduced the Landscape of Creators and how closely tied it is to the sense of self, we can delve into the three rules that Self-Doubt follows to manifest itself in us. And of course, it’s fitting that Rule #1 has everything to do with the way we view everyone in this landscape.
This simple mechanism is the initial way for Self-Doubt to slip in. Whenever the gap between what you’re doing and what others have done widens, it will feel natural for you to question your progress, and whether or not you’re making any forward movement at all.
But what’s interesting is that this gap is determined by your perception of where you stand relative to others, and not what may actually be the case. For example, someone you perceive to be way ahead of you may actually believe that you are much further along than them.

The reason this happens has to do with the asymmetrical nature of creativity.
For any piece of work in question, there are two opposing sides in which it is perceived: one from the side of the viewer, and the other from the side of its creator.
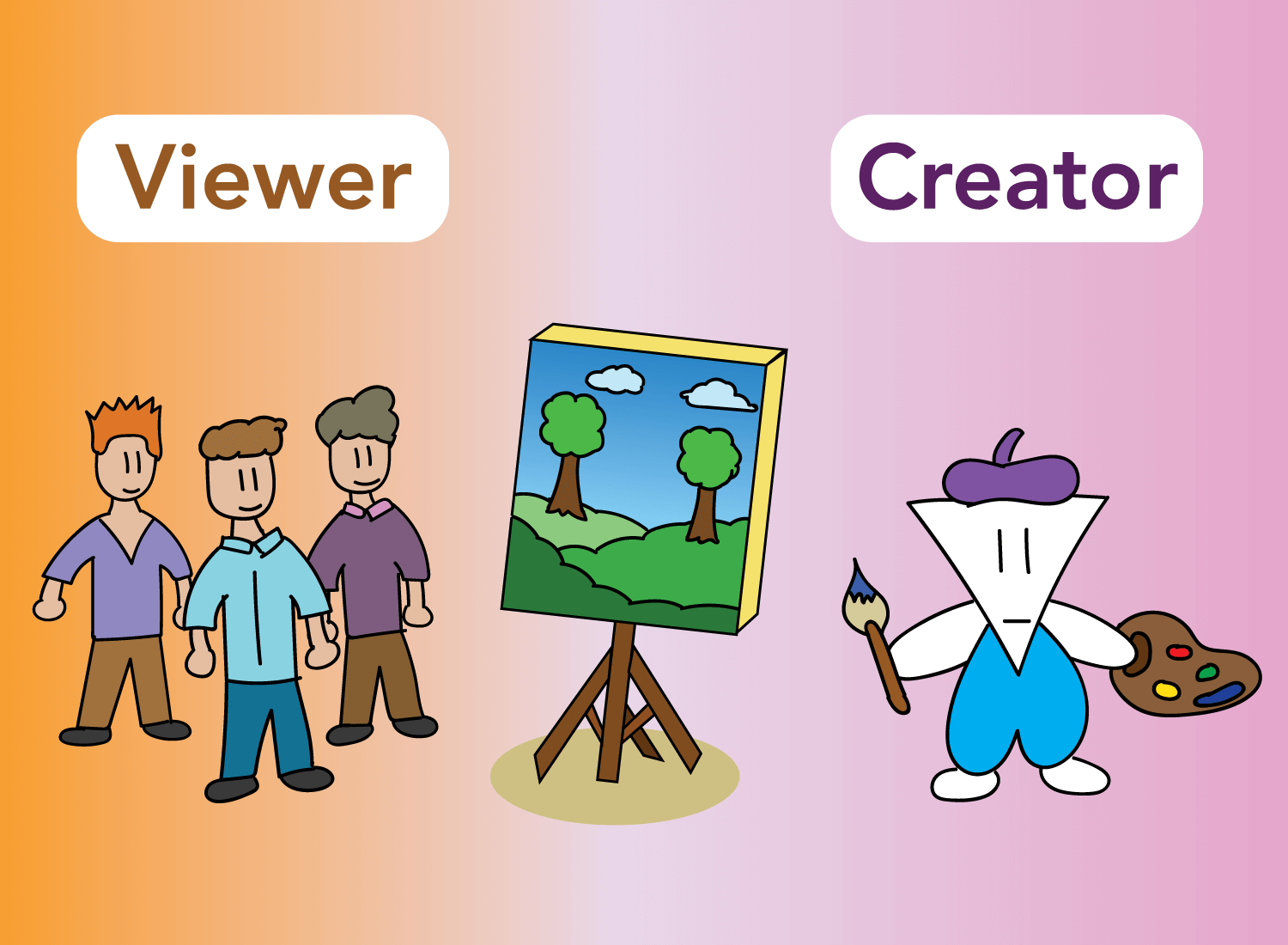
The viewer can only see the finished product – the polished result that is being presented to the general public. The viewer doesn’t see all the failed prior versions, the countless hours of practice, the trashed drafts, or the sleepless nights that went into building what’s on display.
The only thing that matters to the viewer is how that song sounds when it’s uploaded, how the final cut of that film flows, or how that book reads when they pull it off the shelves. Everything is seamless to the viewer, as the quality of the end result of is all that matters.

The side of the creator, however, is a beautiful mess that only you must navigate. As a creator, you have to go through every daunting step of the process to take that seed of an idea that once lived in your brain, and turn it into something you’re proud of that you can present to others.
Each step of this process is an exercise in determining what feels right and what doesn’t, when to take influence from others and when to ignore them, and when to move forward and when to cut your losses.
As you can imagine, each of these steps are ripe opportunities for Self-Doubt to come in and hijack the whole ordeal. In the end, a creator must make choices with conviction, but it’s natural for doubt to live between the spaces of those decisions. After all, second-guessing yourself is second-nature when your work means so much to you.

Doubt and uncertainty are natural obstacles for any creator, but when we view others’ work, what we see is confidence and finality. This is because we will always be viewers of others’ work, but the sole creator of our own. We are constantly comparing the completed works of others to the jagged and messy routes of ours, and this leads us to overestimate everyone else’s abilities:

While we simultaneously underestimate our own:

The reality is that everyone else is just as doubting and uncertain as you are, but you can’t see that because you don’t live in their heads. This inability to reconcile the difference between being a creator and a viewer creates the illusory gap that Self-Doubt lives in, which leads us to the next rule that it loves to follow:
If the first rule explained why we doubt ourselves in relation to others, this second rule is what internalizes that doubt into something destructive.
Envy is a complicated emotion that has its roots in survival and sexual selection, but in the domain of creative work, it has an especially sinister quality that makes it such a negative force for us.
Creativity is largely about community and communication – even if most of your work is done in isolation, it has no wider impact if it’s not shared with people, and the work you do is largely influenced by the contributions of others. Relationships – whether personal or intellectual – are the forces that shape what’s important to you, and the closest ones drive that sense of belonging the most.
Given this, envy has learned a devious trick that threatens to destroy this sense of community altogether.
Envy has this nasty ability to flare up strongest amongst people you are closest to, primarily because it only appears amongst folks you can readily compare yourself to. So counter-intuitively, it is strongest amongst peers, friends, and family:

And weakest amongst those that may be enormously successful, but are too far removed from your way of life:

Philosopher Bertrand Russell summarizes this phenomenon well:
Beggars do not envy millionaires, though of course they will envy other beggars who are more successful.
Envy takes a group of familiar and loving faces that should make up our support systems, and instead warps them into sources of inadequacy that only makes us doubt ourselves even further.
If Rule #1 creates a perceived gap between you and other creators, Rule #2 solidifies that gap by turning you away from the people that matter most. Ultimately, all we really have are our peers, friends, and family members, but if you perceive their lives through the lens of envy, your sense of progress will always be relative to theirs, and you will view them as sources of competition rather than beacons of inspiration.
It is here where Self-Doubt can grow so large that its voice becomes thunderously compelling. Not only do you think you’re underperforming the expectations you’ve set for yourself, but you also cannot find solace and comfort in those closest to you because envy has taken over.
This is where Self-Doubt leaps to deliver its final blow in the form of its final rule:
In many ways, pursuing any meaningful endeavor is a vote for the rocky path of uncertainty. Not only is fiscal stability a big question mark, but it’s unclear whether or not an audience may even exist for your work in the first place.
There will be moments where it feels like no one cares about what you’re making, despite all the energy and effort you’re putting in. It will feel like the only response to your work is a deafening silence that echoes out violently, making you question why you’ve chosen to spend any time on this endeavor at all.

If you combine this with the belief that everyone is more capable than you are (Rule #1), it will only seem rational to quit. After all, what’s the point of slogging through this pit if you can instead do something else that has a more predictable outcome? And what if you can’t help but to feel envious of the people you’re closest to (Rule #2)? Doesn’t quitting sound like the most sensical thing to do in this position?
These are the fatal questions that Self-Doubt throws to get you off this journey for good. And for many people, these questions will sound compelling enough for them to accept the end of the road, pack up their bags, and walk away with no return date in sight.

This ability for Self-Doubt to sound like the rational voice of reason is its grand finale – the greatest tactic it uses time and time again to prevent people from doing work they love and from reaching their potential.
But like all the other nonsense it spews, it’s just one big devious trick.
The thing about Self-Doubt is that it lives solely in the now; it knows nothing more than what can be seen and experienced at this precise moment. It can’t envision any sort of future where results grow over time, where your confidence builds with each thing you make, and where your insecurities soften as you progress onward.
Instead, it takes all the frustrations you’re experiencing today and makes it feel like things will always be this way. It sees that you spent ten hours making a blog post that only five people saw, and will convince you that every single post you create afterward will have the same result. It tells you that today’s results will be tomorrow’s inevitabilities, and that these results will extend out to all the months and years to come.
But of course, the truth is far from that. All meaningful endeavors and careers take time to shape and develop, and this type of long-term thinking is something that we all have the power to understand. However, when Self-Doubt hijacks our journeys, it makes us believe that the results we are experiencing today will run onward in perpetuity…

…when in reality, this is just a small subsection of a much longer time horizon that looks more like this:

When you’re doing meaningful work, you must be able to trade short-term disappointment for long-term progress. While it may seem irrational to continue pursuing this path today, everything will only make sense when enough time has elapsed so you can see how far you’ve traveled.
In my case, whenever I doubt myself based on current results, I try to remember that I must view my writing career through the lens of decades, not days. So if a post I created today didn’t resonate with anyone – oh well – it’s just one of many that I will do over the course of a longer timeframe. Even if things feel stagnant for a while, I can understand that I’m still quietly building the foundations for a period of growth that has yet to come.
Whenever we can frame the creations of today as necessary steps for the future, we can silence Self-Doubt’s cries for attention. If we can commit to playing the long-game, this acceptance of patience brings a clarity that will keep you focused and ready for the challenges that await you today.

So there you have it – the three simple rules that Self-Doubt operates under. They’re not sophisticated by any means, but they’ve been remarkably effective at preventing us from doing work that matters.
But now that we know all the tricks Self-Doubt uses on us, here are three things to keep in mind to successfully silence it:
(1) Stop being so hard on yourself, and give yourself credit where it’s due. Only you have access to the behind-the-scenes struggles that come with doing your work. Whenever you compare yourself to others, remember that you’re seeing their finished product, while you’re feeling the pain of each step of the creative process. It’s not a fair comparison, so don’t use it to base your judgment on whether or not you’re doing great work.
(2) Do away with envy, and be inspired by your peers instead. Envy’s greatest trick is to flare up strongest among the people you’re closest to. Instead of feeling inadequate around the company of your peers, recognize envy as the deceiving little bastard it is, and replace it with gratitude for these people around you. View their life journeys as inspirations for what is possible, and become a more empowered creator as a result.
(3) Ignore short-term results, and play the long game instead. If you’ve found something you love working on, chances are you want to stay there for a long, long time. So even if you’re not seeing the results you want today, just know that you’re slowly building yourself an on-ramp to future progress. As long as you can view your endeavor through the lens of decades and not days, you will be able to silence Self-Doubt and continue working on the things that make your life so meaningful.
_______________

If you enjoyed this post, consider joining the More To That email list. We’ll treat your inbox/digital home with the respect it deserves, and will only send you emails when a new post goes up.
If you want to support the many hours that go into making these posts, you can do so at our Patreon page here.
_______________
If financial worries are causing you to question yourself, then this big post will help clear things up:
Money Is the Megaphone of Identity
Another way to overcome doubt is to find gratitude in the challenges that await you:
Thankfully, Life Is Full of Problems
And why the best time to pursue your endeavor is now:
The post Why We Doubt Ourselves appeared first on More To That.